
The Paths Forward
In Container Portability: Part2: Code Portability Today, we discussed how there are no regression tests, there is no complete interface standard, there is definitely pain ahead if we think we can use today’s container images (level 3B) on tomorrow’s container hosts (level 3A), 10 years from now. So, what’s the solution?
With the adoption of container images as a unit of portability to deliver applications, we now have to manage operating system dependencies in two places – in both 3A and 3B. The dependencies for the container engine, container orchestration and anything else installed directly ominn the container host are managed using the tools provided by the underlying operating system (RPM, Deb, Packages, System Containers, etc). Stated simply, the container host comes with all of its tools, so we don’t have to worry about that. But, we also have operating system dependencies embedded in each of the container images and there have to be tools to manage those as well.
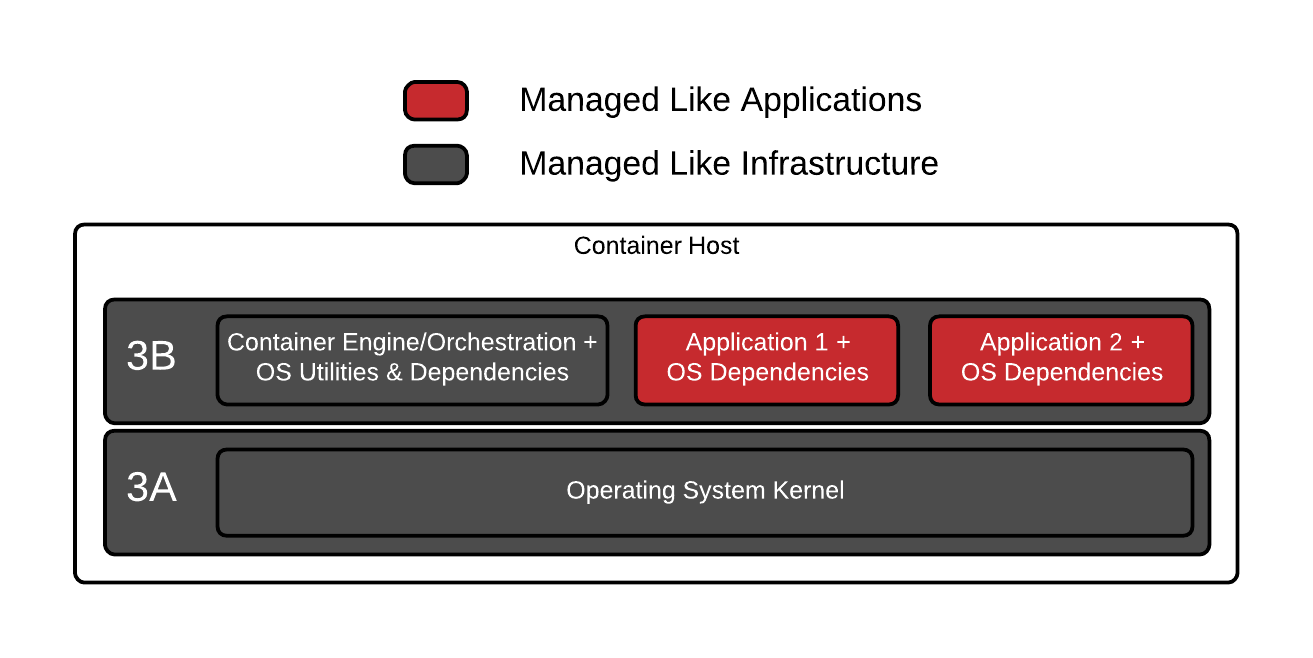 Systems administrators are responsible for container host upgrades, downgrades, and fixes to this underlying infrastructure. This is pretty easy, it doesn’t really change too much – use a standard operating environment and a standard patching policy.
Systems administrators are responsible for container host upgrades, downgrades, and fixes to this underlying infrastructure. This is pretty easy, it doesn’t really change too much – use a standard operating environment and a standard patching policy.
Things get hairy with all of the operating system dependencies, libraries, utilities, etc embedded in each container image. User facing applications rely on them and they must be updated somehow. Since container image layers are inherently static, the dependencies embedded in them will inevitably age like cheese, more than wine. That means, there needs to be a tool to update the dependencies themselves (RPM, Deb, etc), but there also has to be a system to rebuild all of the dependent container images. In the container images have things like Glibc, encryption libraries (and their configuration for certification e.g. FIPS 140-2), and even libraries that allow access to specialized devices or hardware accelerated routines/functions. These types of libraries can be very sensitive to what hardware is available in a container host, the kernel configuration, the kernel version, and even what kernel modules are loaded.
So, I see a few main paths forward which seem sane:
- Build a standard operating environment like you always have. This needs to cover the container host, the container engine, container orchestration, and what’s in the container images. Portability is a business requirement, while compatibility can only be guaranteed by technical planning. Stated simply, as long as you run the same Linux distribution everywhere, you will be able to move those Linux containers anywhere that Linux distribution is run. If you have Fedora 26 running on premise and on AWS, you can reasonably guarantee that your application containers will run on premise and in AWS. As I have advocated before, today, I recommend using the same versions of Linux for all of your container hosts, container images. I also recommend that you use the container engine that was built and tested with your Linux distribution. Don’t mix and match your own custom Linux distributions and container engines or you will be going off the beaten path. A standard operating environment is the easiest and most reliable path to take today.
- Test and mitigate everything yourself. If you are going to mix and match Linux distributions on the container hosts and in the container images, you really, really need to start building expertise right now. Start testing everything. As you find failures, document failures and mitigations, and finally build tests to catch them in the future. The most challenging part of this path is mitigation. There will inevitably be tough compatibility problems that you will run into, and finding a work around may be very difficult. For example, a bug that causes a kernel panic in the underlying container host (this really happened to a customer). Figuring out a work around can be difficult if you don’t have really technical people on staff, like kernel programmers.
- Jump into the community and let’s start figuring this out. Let’s figure out what all of the interfaces look like today, and what they need to look like tomorrow to guarantee portability. This might involve constraining the system call table to versions, as well as stopping applications form accessing /proc or /sys. Setting a standard here would require a lot of work. There are also some very challenging technical problems. Years ago, I brought up that there is no way to figure out which system calls an application may need because it’s a Turing Complete Problem – this is because a user could write a Python script that literally calls anything with the system() method. With C and Assembly code, it’s even worse, you can vector any system call using the full table, even undocumented ones. Interestingly, this is something the people like to do to optimize for speed – Golang does this in some places.
So, the solutions today, are quite simple – you can achieve complete portability by planning correctly. With containers it’s more important than ever. As a final challenge, ask somebody you know at Google, Facebook, Amazon, or Twitter if they have a standard operating environment across their millions and millions of machines? The answer is definitively, yes. You should do the same to achieve portability with containers.
ADDENDUM: If you didn’t study computer science in college, I would highly recommend reading Structured Computer Organization 6th Edition by Andrew S. Tanenbaum. Coincidentally, Tanenbaum is the guy that wrote Minix and wouldn’t open source it – so Linus went and wrote Linux. Nonetheless, Tanenbaum is still wicked smart and shares a tremendous amount of knowledge. You can read the PDF for the 5th edition here, which is the version I used many years ago in computer science. Do yourself a favor and spend a few hours reading the first chapter, and everything I have said about container portability will click.
MINIX, not Minux…
Tough…but fair 🙂 So used to typing Linux 🙂 #fixed
Awesome doc! Thank you so much for taking the time to write it.