Background
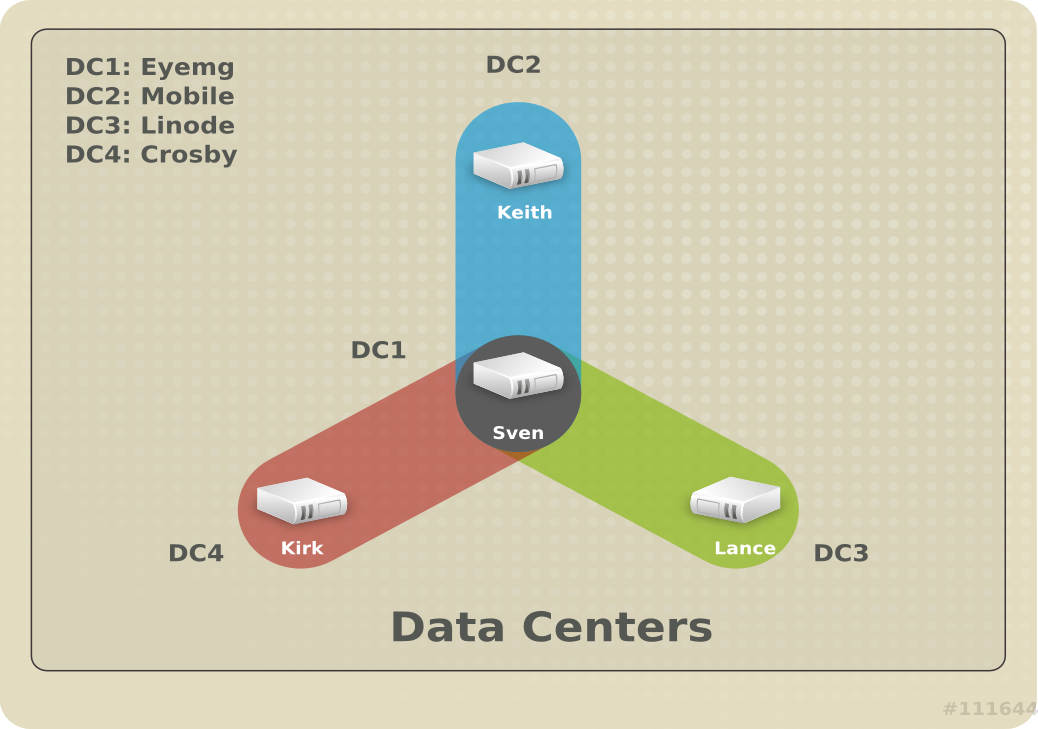
Last week, I was in Westford, MA for an engineering meeting. I was chatting with one of our Base Runtime engineers Petr Sabata, and an interesting subject came up. He joked, “I understand containers, I know how to use them, but I still haven’t converted any of *my* services to containers.” This got me to thinking – you know what – I haven’t converted any of *my* services either. Like any former systems administrator, I run my personal setup like a data center – I have instances of Mediawiki, WordPress, Request Tracker, Subversion (server), Nagios, Cacti, and a bunch of other supporting services running in four different geographic locations. All of it’s monitored, and I get paged if something is down (I just can’t let go :-P). For all intents and purposes, this stuff is production. If my ticket system or wiki is down, I am dead in the water. This makes these services very sensitive to move. I need to make sure I figure out the big stuff like backup/restore, monitoring.data acquisition, updates as well as simple things like, how does an administrator do the equivalent of extending an LV when it’s mounted on a PV in OpenShift? To be very honest, every time I plan to migrate, I get road blocked at some point.
And So It Begins
This weekend, I got motivated – my three node OpenShift 3.4 installation is now up and running. I threw caution to the wind, dove in. I am well aware that I ignored some of the best practices to get this thing installed and running, so please don’t judge me 🙂 I started by getting three instances of RHEL 7.3 running in Linode. This took some hacking because RHEL is not supported on Linode. You have to build your own image. Then, I troubleshot some strange things like network interfaces being recognized as eth0 on one server, but esn3 on the others. After the lower level stuff was solved, I got the container runtime installed and configured. I am just using device mapper loop deviceS for now because of resource constraints in Linode (I know, I know, bad….). Ignoring the minimum requirements, I then got OpenShift installed, up and running. For those that want to see the commands I used, here is the pastebin of the commands.
Finally, you will notice, I prepped everything manually. This is because my standard operating environment for years has been built with Satellite and Puppet. Well, my Satellite server is dead (cascading failures) and I want to convert to Ansible. So, I am collecting all of the operations that I will need first, and I will automate later. This is a standard pattern, and anybody that says automate first, doesn’t understand engineering and ROI. Experiment, experiment, then build automation. I wrote a three part article about how to do real engineering explaining documentation and automation Yes, you *still* and *always* need to document the entry point into automation and how to commit changes to it. This is basically the root of why S3 failed a couple weeks back – people aren’t careful with the entry point into automation and destroy things, much faster. But, I digress.
Conclusion
Well, stay tuned over the coming weeks as I tackle each of the necessary technical requirements to run containers in production. First, I need to figure out how I will architect my projects in OpenShift and how I will build my image layers to support all of the different applications which I have. After that, I will start migrating services along with all of their supporting functions like backups, monitoring, data acquisition. Nagios and Cacti going to be interesting considering it has always been a CPU hog and will probably need broken apart somehow. The goal is to not get into some cascading chaos where I pick all new services just because I am moving to containers. There is the engineering desire to check out something like Zabbix, etc, but I will attempt to change as little as possible because these are the constraints of real operations people at real companies.