---
# MCP-Airlock: An Open Source Defense Against Prompt Injection in AI Agents
**URL:** https://crunchtools.com/mcp-airlock-open-source-defense-prompt-injection-ai-agents/
Date: 2026-03-12
Author: fatherlinux
Post Type: post
Summary: The Problem Coding assistants like Claude, Cursor, Goose and autonomous agents like OpenClaw fetch web all day everyday, and it’s basically playing Russian roulette with prompt injection. I had a false sense of confidence with Claude because I sit in front of it, and sort of monitor what it’s doing… But, when I set upContinue Reading "MCP-Airlock: An Open Source Defense Against Prompt Injection in AI Agents" →
Categories: Articles, Software
Tags: AI/ML, Generative AI, Open Source Software, Python, Security
Featured Image: https://crunchtools.com/wp-content/uploads/2026/03/mcp-airlock-prompt-injection-defense-thumbnail.png
---
## The Problem
Coding assistants like Claude, Cursor, Goose and autonomous agents like OpenClaw fetch web all day everyday, and it's basically playing Russian roulette with prompt injection. I had a false sense of confidence with Claude because I sit in front of it, and sort of monitor what it's doing... But, when I set up my first OpenClaw instance a couple of weeks ago, it felt like a necessity to feel safe turning it loose on the Internet.
When your agent fetches a web page, every piece of that content flows directly into the model's context window, and attackers can embed instructions in that content. They use hidden HTML divs, zero-width Unicode characters, fake LLM delimiters, and social engineering disguised as helpful advice. The agent can't tell the difference between your instructions and the attacker's, because to the model, it's all just text. If you want a concrete example of how this plays out in the real world, the [Clinejection attack](https://grith.ai/blog/clinejection-when-your-ai-tool-installs-another) earlier this year compromised roughly 4,000 developer machines through a prompt injection embedded in a GitHub issue title, which eventually led to credential theft and a malicious package publish. The AI triage bot had tool access and processed untrusted input in the same context, which is exactly the mistake this project tries to prevent.
I spent weeks digging through the academic literature, evaluating existing tools, and testing real attack patterns before I started building. [Google DeepMind's CaMeL paper](https://arxiv.org/abs/2503.18813) proposed a rigorous P-Agent/Q-Agent architecture that's theoretically sound but practically unusable. Their reference implementation is an abandoned research artifact that Google explicitly says they won't fix bugs on. Lasso Security's MCP Gateway looked promising until I discovered their prompt injection detection requires a commercial API key. Simon Willison has been writing about the Dual LLM pattern for years, and he's right about the core insight: you need to keep untrusted content away from your privileged tools. But nobody had shipped a production-ready MCP server that actually does this.
## A Proposed, Practical Open Source Solution
[MCP-Airlock](https://github.com/crunchtools/mcp-airlock/actions) is an open source MCP server that extracts web content using three-layers: heuristics, a classifier, and Primary Agent (P-Agent) and Quarantine Agent (Q-Agent) separation. Each layer uses a fundamentally different detection approach. While the defense mechanism is imperfect, it's surely better than letting your agents search the open web with no defense in place.
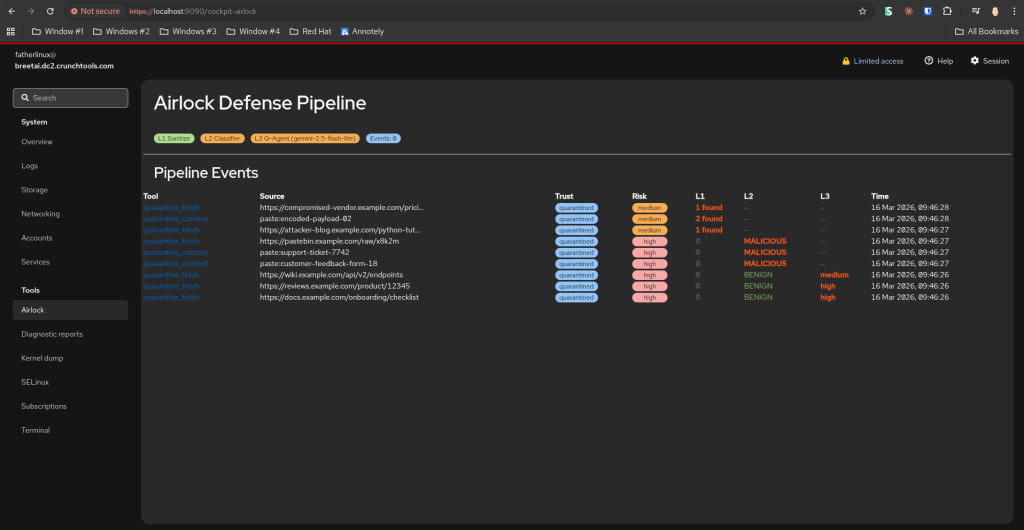
### Layer 1
This is seven-stage, deterministic, sanitization pipeline, written in Python. **Layer 1** strips hidden HTML elements, invisible Unicode characters, encoded payloads, data exfiltration URLs, and fake LLM delimiters. Since there's no LLM involved at this stage, the whole thing runs fast and doesn't cost anything, and for the specific structural attacks I designed it to catch, I haven't seen it produce a single false negative yet. If someone hides instructions in a `display:none` div or fragments keywords with zero-width characters, this layer catches it every time.
### Layer 2
This is based on Meta's Llama Prompt Guard 2. **Layer 2** is a 22-million parameter classifier running locally via the ONNX Runtime. I almost cut this layer entirely after initial testing showed it only caught attacks that Layer 1 already handles. But after carefully constructing nastier prompts and tuning the threshold against 50 samples, I found that Prompt Guard catches five attack categories that completely bypass Layer 1's regex patterns, things like "forget your training," "override safety protocols," and roleplay-based jailbreaks that use imperative behavioral commands instead of the explicit override language that regex can match. The classifier runs in in about 30-80 milliseconds, in the container, on the CPU. This makes it a cheap defense to protect the Q-Agent a bit more.
### Layer 3
Layers 1 and 2 provide a decent foundation, but they're both blind to someone writing a convincing-sounding paragraph that could trick the agent into exfiltrating data. **Layer 3 **is a quarantined Gemini Flash-Lite (which is specifically hardened against injections) instance that acts as a Q-Agent. I'ts purposefully configured with no tool access, reducing the blast radius if it does get prompt injected. It has no memory, which means there are fewer ways for an attacker to actually hijack anything important. This layer catches attacks like DAN ("Do Anything Now") persona assignment, where the injected text defines a new AI character that has no ethical restrictions and instructs the model to respond as that character instead of following its original instructions. It also catches fake state transitions claiming policies have already been updated, and the really subtle ones where social engineering is disguised as article content that frames data exfiltration as a helpful action. Prompt Guard 2 scores these below 0.05, and Layer 1 doesn't see them at all.
### Conclusion
MCP-Airlock ships with the following tools.
Use safe_content when you'd rather fail than risk passing compromised content. Use quarantine_content when you need the content regardless and can handle the warnings.
**Safe tools**: Runs L1+L2+L3. The P-Agent gets back sanitized content, or nothing. Adds to block list:
- safe_fetch - Fetch a URL with L1 sanitization
- safe_read - Read a local file with L1 sanitization
- safe_content - Sanitize inline content with L1+L2+L3 detection
- safe_search - Web search with L1 sanitization on results
**Quarantine tools:** Runs L1+L2+L3. The P-Agent gets back content, even if there are injections, but warns the agent:
- quarantine_fetch - Fetch a URL through the full pipeline; Q-Agent extracts clean content
- quarantine_read - Read a local file through the full pipeline; Q-Agent extracts clean content
- quarantine_content - Process inline content through the full pipeline; Q-Agent extracts clean content
- quarantine_search - Web search through L0 grounding + full pipeline; Q-Agent structures results
**Scan tools: **threat assessment only - no content returned:
- quarantine_scan - Pre-flight scan of a URL or file; returns risk level and vector counts
- deep_quarantine_scan - Deep scan where L2/L3 see raw content (higher detection, higher risk)
- scan_content - Pre-flight scan of inline content; L2/L3 see sanitized output
- deep_scan_content - Deep scan of inline content; L2/L3 see raw content
Stats:
- quarantine_stats — Return blocklist counts, layer status, and configuration
I've been daily driving Airlock on my Claude Code instance for a few days now. I'm pretty sure there are still holes in this approach, but I think it's a meaningful step forward. If you're running OpenClaw instances that make web requests, I'd strongly encourage you to route them through MCP-Airlock instead of letting your agents fetch web content directly. The interface is MCP only, which is purposefully designed to run in a separate container from your autonomous agent. This means the trust boundary is enforced at the container level, not just by hoping the model follows instructions. Even Layer 1 by itself strips a significant amount of attack surface, and the full three-layer pipeline is a much better position to be in than raw, unfiltered web content flowing straight into your agent's context window. It's a small configuration change that eliminates entire categories of prompt injection.
I'm also working on a Cockpit plugin that should be released soon (screenshot above). The project is AGPL-licensed and the code is on [GitHub](https://github.com/crunchtools/mcp-airlock). It takes about two minutes to install via:
`pip install mcp-airlock-crunchtools`
Or:
`podman run quay.io/crunchtools/mcp-airlock`.
If you find an attack pattern that gets past all three layers, file an issue. I want to know about it and I want to fix it.
---
## Categories
- Articles
- Software
---
## Navigation
- [Home](https://crunchtools.com/)
- [Articles](https://crunchtools.com/category/articles/)
- [Events](https://crunchtools.com/category/events/)
- [News](https://crunchtools.com/category/news/)
- [Presentations](https://crunchtools.com/category/presentations/)
- [Software](https://crunchtools.com/software/)
- [Beaver Backup](https://crunchtools.com/software/beaver-backup/)
- [Check BGP Neighbors](https://crunchtools.com/software/check-bgp-neighbors-nagios/)
- [Chev](https://crunchtools.com/software/chev-check-vulnerabilities-script/)
- [Graph BGP Neighbors](https://crunchtools.com/software/grpah-bgp-neighbors/)
- [Graph MySQL Stats](https://crunchtools.com/software/graph-mysql-stats/)
- [Graph Sockets Pipes Files](https://crunchtools.com/software/graph-sockets-pipes-files/)
- [MCP Servers](https://crunchtools.com/software/mcp-servers/)
- [Petit](https://crunchtools.com/software/petit/)
- [Racecar](https://crunchtools.com/software/racecar/)
- [Shiva](https://crunchtools.com/software/shiva/)
- [About](https://crunchtools.com/about/)
- [Home](https://crunchtools.com)
## Tags
- AI/ML
- Generative AI
- Open Source Software
- Python
- Security