
Recently, I read another article that critiqued Kubernetes as having a steep learning curve. At conferences, I also hear a lot of people in the Kubernetes community talk about how we need to make it more easy to onboard people. While I think it’s a noble goal to make Kubernetes more usable, I don’t think we should do it at the expense of long term elegance in design. Here’s why.
My experience started in 1999 running things like HTTPD, DNS, NFS, HPC schedulers, MySQL, Perl/Python/Ruby, BGP, routers, switches, and firewalls – at places like NASA Glenn Research Center, Altel (now owned by Verizon), American Greetings E-Cards, and Eyemg – which shaped how I look at running things at scale. I have scaled applications vertically, and horizontally. I have ran giant (at the time) SGI boxes with 35 processors, and clusters of 1000 x86 servers. I have written thousands and thousands of lines of code, and participated in countless architecture meetings (we didn’t have the word DevOps until I worked at Eyemg). Now, I work at Red Hat and I think about Kubernetes and containers daily – and I talk to a ton of customers, ranging from telco and financial services, to public sector and auto manufacturers.
In all of this, you start to see the same problems come up, time and time again. Things like Unikernels, Serverless, and containers are all just novel ways to solve the same computing problems we have always had – and many of them are very specialized which means they only work well for a small subset of the problems we face in development and operations.

When I think of scale, I think of 1000 servers, but also 75 different IT systems. What I mean by that is – you don’t just run web servers – you don’t just run web apps. In a fully matured IT environment, there is much more than just the business facing web servers. There’s the back end network devices (routers, switches, firewall) – even if virtual in AWS. There’s the specialized utilities and tools that connect to the network devices, or manage them at scale. There are the Integrated Lights Out cards, the special software to manage the Oracle Database – the special software to help normalize the Oracle Database. There are the tools to pull some of the data out of Oracle and move it into MongoDB, and then on to Hadoop.
The front end web services are some of the easiest things to run. A PaaS is fine for that. A PaaS is a Ferrari – it’s red, fast, and sexy. It has two seats and it’s great for showing off in, or taking through the mountains every now and then. It’s specialized. It’s terrible when you go to the grocery store. It’s even worse when you go to the home improvement store. It’s absolutely useless with three kids, and a dog.
IT systems are no different. Pivotal Cloud Foundry is a sexy, red Ferrari. It demos great. It has really sticky tires, so it performs well on the track. It’s near useless for stateful applications, and completely useless for EVERYTHING else in your IT environment. You don’t run glue programs in PCF, you don’t run tools, you don’t run HPC workloads, you don’t run network scanning tools, etc. It’s very specialized and focused on web apps. It’s good at that, but not much else. Adding stateful storage is like adding a pop-up trailer to a Ferrari. Never seen that.
Other tools are more flexible. CF Engine is 20 ton dump truck, it’s pretty useful for carrying a lot of different materials, but it’s hard to park in city streets. Ansible, Chef, and Puppet, are 10 ton dump trucks that are more manageable – Ansible can even manage network devices. Actually, Ansible is a Swiss Army Chainsaw (TM) and people love it because of that 🙂 People also like flexible tools because they can learn one, and get a TON of mileage of it.

Kubernetes – well, Kubernetes is a 10 ton dump truck, but it handles pretty well on the track at 200mph (321 kph). Yes, you might need a Commercial Drivers License (CDL) to legally drive it, but we are all professionals here. Race car drivers have special licenses to get on race tracks. Truck drivers have special licenses to drive on public roads. Crane operators have certifications. The point is, yes – there is a learning curve for really powerful tools. Kubernetes is very powerful and elegant – and that’s why I love it. It can be used to run a broad swath of workloads in an IT environment. It can contribute to standardizing, as opposed to having “another” management system.
I am tremendously excited by containers and Kubernetes because they have the potential to run almost anything. DNS, no problem. Crazy, five way replicated Galera MySQL, no problem. Network scanning tools, no problem. HPC workloads, yeah, that sounds do-able. Java, no problem. LAMP, no problem. Specialized Netflow analysis tool that you compiled because your tool can’t create the report you need? No problem. You name it and Kube can run it – and even easier than before. That Netflow tool you compiled in February 2017? It will still run two years later when you haven’t touched it since you compiled it – because it was built as a container image.
So, in short, yes, Kubernetes has a learning curve, but that’s why we love it. We have had PaaS’s for years, and containers still took off. Why? If PaaS is a panacea, then containers shouldn’t have taken off right? They took off because they are flexible, powerful, and elegant. With that, I will leave you with a drawing I made while developing my Linux Container Internals Lab. I created it shortly after I had an epiphany of how powerful Kubernetes is. It allows you to model an entire IT environment. All of the basic patterns are already baked into Kubernetes. It’s opinionated – just enough. Hopefully, this drawing will help with that learning curve people keep talking about….
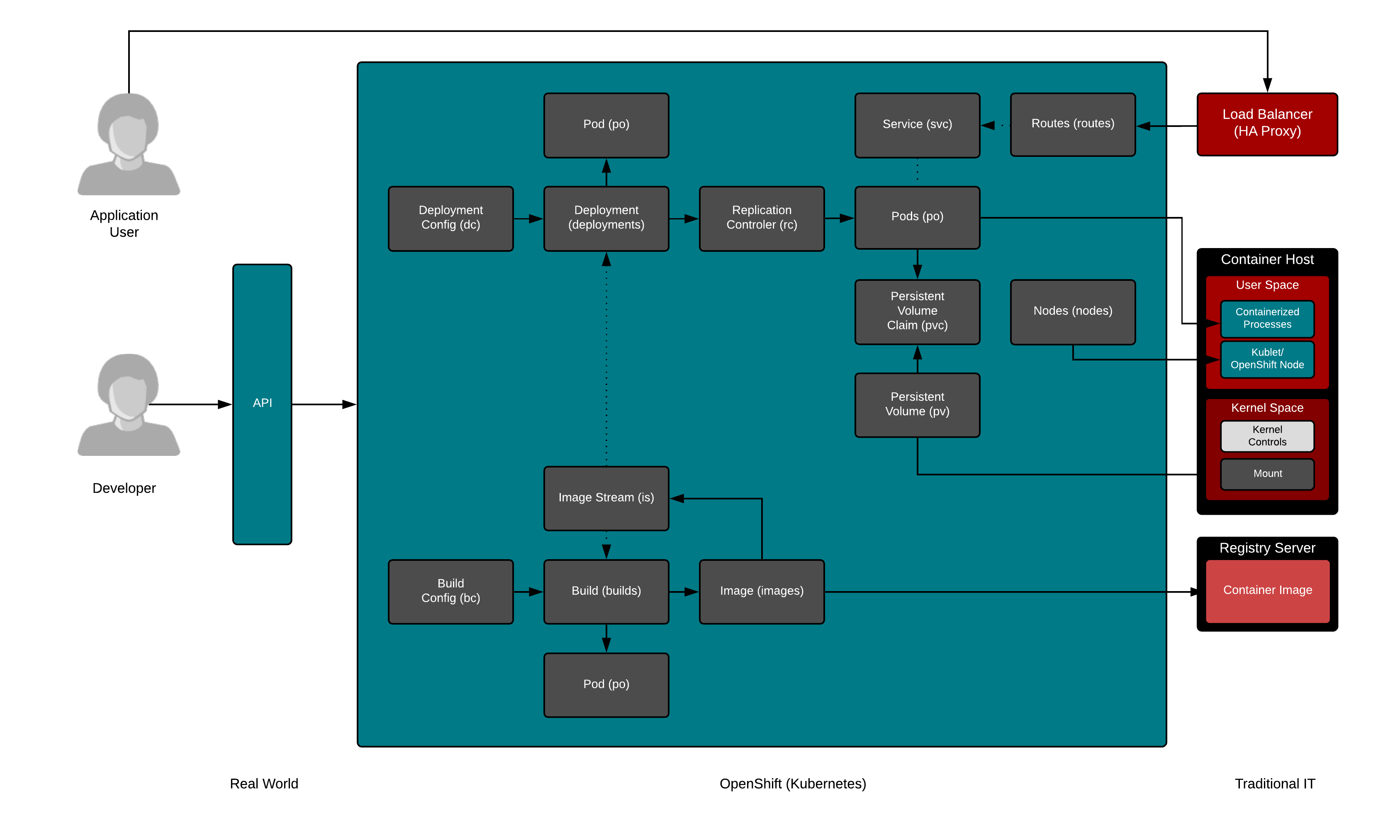
Hah! I think this is the best description of Kubernetes yet!
I think this take is a bit dated – something like Cloud Foundry is more than a PaaS (Kubernetes part of it as the CFCR, as are a slew of marketplace services like MySQL galera clusters, Redis, etc.) , and even a PaaS is more than what you say it is here. … Cloud Foundry absolutely has shared stateful storage , for example, and it’s dead simple to use.
Instead of a Ferrari, I’d say Cloud Foundry is a premium SUV, whereas Kubernetes is a pickup truck. They’re both necessary and great technologies. Car analogies are rough though . 🙂
keep in mind that Web apps, web services, transactional services, mobile services, billing systems, integration systems, etc. are the life blood of your business, change often, and thus great on a PaaS , as that’s what it was designed for – deploying code to cloud with no friction, consume stateful services on demand . That’s a great experience for a developer workflow. For everything else, yep, Kubernetes is definitely a great step up from plain old VM’s, but it’s still early days before people are running Oracle clusters in prod on Kubernetes.
I’ll admit car analogies are rough, but…. If PaaS, or as you say “more than PaaS” was what people wanted, Docker wouldn’t even be a thing. This is basic deduction. Docker achieved world altering traction because PaaS was too much – so one can assume that more than PaaS was way too much 😉
Also, don’t disagree on early days. The “Container Wars” still haven’t played out, but I am pretty happy with Red Hat’s position with the CoreOS acquisition 😉
Also, I just wrote this a while back, so it’s not that dated – perhaps my knowledge of Cloud Foundry is dated 😉
At the end of the day Kubernetes is bolted on piece of tech for Cloud Foundry. They aren’t major contributors, and they have constantly changed their tech over time to try and stay in the game. I agree, that the 10 ton, 200 mph dump truck needs seats, interior and maybe a radio, people didn’t want a premium SUV. They wanted something industrial, hence The Container Wars.
There’s always a balance. Also, I agree it’s going to be a while until we have Oracle database running in prod on Kube, which means it will be never for CF 🙂 I think the gravity is around Kubernetes, Helm, Service Broker, Operators, etc, etc – the Kubernetes Community is the gravity. Bolting it on to CF doesn’t work.
Markets evolve in unpredictable ways. Pivotal makes a lot of money selling PaaS , Herold makes a lot of money selling PaaS… there are very happy customers. Certainly it didn’t become a hype train like Docker, but there’s a lot to be said for the local desktop experience, and something relatable vs. this magical framework that takes care of a lot of stuff. But now we see AWS Lambda threatening everyone, so perhaps people are open to magic after all? Like I said, it’s not so simple to say PaaS is a dead thing.
As for Kubernetes being bolt on to Cloud Foundry, that’s not exactly fair, certainly Pivotal didn’t have first mover on Kubernetes the way RedHat did, but the reason was focusing on growing a business with the platform as is, which grew massively. My understanding is that PCF customers asked for BOSH managed Kubernetes and that led directly to Kubernetes in. CF. Let’s also keep in mind that a Google has full time engineers on CFCR. also, I might remind you that OpenShift has been rewritten 2 times to stay in the game 🙂
I’m happy to see competition in the world, it’s great there are very different visions out there between Amazon, Redhat, Pivotal, Microsoft, or a Google, and I hope ISVs like the Redhats and Pivotal’s of the world continue to grow and thrive from the big 3 clouds. It’s in everyone’s interest imo..
That should say heroku not Herold!