Background
At JUDCon 2013 in Boston, Scott Cranton and I presented a talk entitled Resilient Enterprise Messaging with Fuse & Red Hat Enterprise Linux. This technical article is the follow up work from that presentation.
JBoss A-MQ is built on ActiveMQ which is a robust messaging platform that supports <http://crunchtools.com/resillient-messaging/a href=”activemq.apache.org/stomp.html”>STOMP, JMS, AMQP and modern principals in Message Oriented Middleware (MOM). It’s built from the ground up to be loosly coupled and asynchronous in nature. This provides ActiveMQ with native high availability capabilities. An administrator can easily configure an ActiveMQ master/slave architecture with a shared filesystem. In the future this will be augmented with Replicated LevelDB.
Red Hat Enterprise Linux is a popular, stable and scalable Linux distribution which has High Availability and Resillient Storage add-on support built on CMAN, RGManager, Corosync, and GFS2. High Availability and Resillient Storage expand upon the high availability capabilities built into ActiveMQ and provide a robust, and complete solution for enterprise deployments that require deeper clustering capabilities.
There are two main architectures commonly used to provide fault tollerance to a messaging server. The first is master/slave which is easy to configure, but as it scales, it requires 2X resources. The second is made up of active nodes and redundant nodes. The redundant nodes can take over for any one of the active nodes should they scale. The active/redundant architecture requires more software and more initial configuration, but uses N+1 or N+2 resources as it scales.
This article will explore the technical requirements and best practices for building and designing a N+1 architecture using JBoss A-MQ, Red Hat Enterprise Linux, the High Availability Add-On and the Resillient Storage Add-On.
Scaling
The native High Availability features of ActiveMQ allow it to scale quite well and will satisfy most messaging requirements. As the messaging platform grows, administrators can add pairs of clustered servers while sharding Queues and Topics. Even shared storage can be scaled by providing different LUNs or NFS4 shares to each pair of clustered servers. The native High Availability in ActiveMQ provides great scaling and decent fault resolution in smaller environments (2-6 nodes).
As a messaging platform grows larger (6+ nodes), the paired, master/slave architecture of the native high availabilty can start to require a lot of hardware resources. For example, at 10 nodes of messaging, the 2N architecture will require another 10 nodes of equal or greater resources for resiliency. This is a total of 20 messaging nodes. At this point it becomes attractive to investigate an N+1 or N+2 architecture. For example, in an N+2 architecture, acceptable fault tollerance may be provided to this same 10 node messaging platform with only two extra nodes of equal or greater resources. This would only require a total of 12 instead of 20 nodes.
Fault Tolerance
The native master/slave architecture of ActiveMQ provides decent fault detection. Both nodes are configured to provide the exact same messaging service. As each node starts, each attempts to gain a lock on the shared filesystem. Whoever gets the lock first, starts serving traffic. The slave node then periodically attempts to get the lock. If the master fails, the slave will obtain the lock the next time it tries and will then provide access to the message queues identical to the master. This works great for some basic hardware/software failures.
As fault tolerance requirements expand, failure scenario checking can be mapped into the service clustering software such as the Red Hat Enterprise Linux High Availability Add-On. This allows administrators to write advanced checks and expand upon them as lessons are learned in production. Administrators can ensure that the ActiveMQ processes and shared storage are monitored, as with the native master/slave high availability, but can also utilize JMX, network port checking things as advanced as internal looking glass services to ensure that the messaging platform is available to it’s clients. Finally, the failover logic can be embedded in the clustering software which allows administrators to create failover domains and easily add single nodes as capacity is required.
From a fault tollerance perspective, it is worth stressing that in either architecture, the failover node must be of equal or greater resources. For example, if the workload running on a messaging node requires 65% of the memory, cpu, or network bandwidth, the failover node must be able to satisfy these requirements. If the workload consumes this amount of resources on the day the messaging platform is put into production, the requirements will typically grow over time. If for example, at the end of two years, the workload has grown to 85%, the workload may now require more capacity than failover node can provide and will cause an outage. It is an anti-pattern to have failover nodes that are not of equal or greater resource capacity than the production nodes.
Architecture
To create an example architecture that demonstrates client to broker and broker to broker message flow, we will configure two brokers as separate services in the clustering software. The producer and consummer will be sample Java code that is run from any computer that has network connectivity to the messaging cluster. Messages will flow as follows:
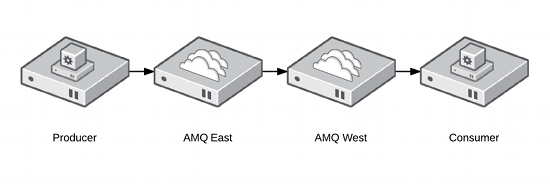
The two services AMQ-East and AMQ-West will be limited to their respective failover domains East and West. This will prevent AMQ-East and AMQ-West from running on the same physical node. Failover domains also allow administrators to architect several failover servers and scale out capacity within the clustering software. For this tutorial, the environment will be composed of the following systems and failover domains.
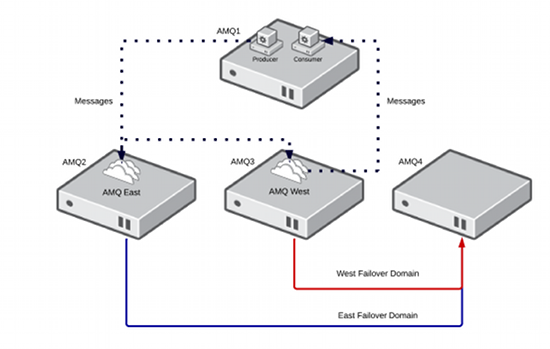
amq01.example.com: Producer and consumer code will be ran here
amq02.example.com: Member of East Failover Domain
amq03.example.com: Member of West Failover Domain
amq04.example.com: Failover node for both domains.
ActiveMQ
The following installation should be performed identically on amq02.example.com, amq03.example.com, and amq04.example.com.
Installation
ActiveMQ is supported by Red Hat in two configurations. It can be ran inside of a Karaf container and is the prefered method in non-clustered environments or if configuration will be managed by the Fuse Management Console (Zookeepr). ActiveMQ can also be ran directly on the JVM. This is the prefered method for clustered setups and is the method employed in this tutorial.
Red Hat provides a tar ball with standalone ActiveMQ in the extras directory
/opt/jboss-a-mq-6.0.0.redhat-024/extras/apache-activemq-5.8.0.redhat-60024-bin.zip
For simplicity the standalone version is installed and linked in /opt
cp /opt/jboss-a-mq-6.0.0.redhat-024/extras/apache-activemq-5.8.0.redhat-60024-bin.zip /opt
cd /opt
unzip apache-activemq-5.8.0.redhat-60024-bin.zip
ln -s apache-activemq-5.8.0.redhat-60024 apache-activemq
Configuration
ActiveMQ comes with several example configuration files. Use the static network of brokers configuration files as a foundation for the clustered pair. Notice that the ports are different by default, this is so that both brokers can run on the same machine. In a production environment, you may or may not want this to be possible.
cd /opt/apache-activemq/conf
cp activemq-static-network-broker1.xml activemq-east.xml
cp activemq-static-network-broker2.xml activemq-west.xml
vim activemq-west.xml
The orignal network of broker configuration files are setup to both run on the same machine. Change default from localhost to the ativemq-east failover ip:
Storage
The storage requirements in a clustered ActiveMQ messaging platform based on RGManager are different than the ActiveMQ Master/Slave architecture. A standard filesystem such as Ext3, Ext4, BTRFS, or a shared filesystem such as NFS or GFS2 can be used. This provides the architect to use the filesystem that maps best to functional and throughput requirements. Each filesystem has advantages and disadvantages.
EXT4
This is an obvious choice for reliability and throughput. There is no lock manager which could provide better performance. An EXT4 filesystem is not clustered and must be managed by the cluster software. This will take extra time during a failover.
GFS2
We have seen good success with GFS2. It allows each node in the cluster to mount the filesystem by default and prevents the cluster software needing to handle mounts and unmounts. This will provide quicker failover during an outage. GFS2 has the advantage of typically residing on Fiber Channel storage and as such is out of band from the standard corporate network.
NFS
Unlike the Master/Slave architecture built in to ActiveMQ, any version of NFS can be used with the clustered architecture. Like GFS2, NFS has the advantage of being mounted at boot, providing quicker failovers during an outage. NFS traditionally uses the standard enterprise network and in my experience may be suseptable to impact by other users on the network.
Clustering
The following installation should be performed identically on amq02.example.com, amq03.example.com, and amq04.example.com.
Init Scripts
These init scripts were developed to be scalable. Configuration data is embeded in a separate configuration file in /etc/sysconfig. As new brokers are added, the administrator can simply copy the wrapper script. For example, camq-west could be copied to camq-north to start a North broker.
Attentive readers may also notice that there are artifacts in this code implying that these scripts are also used for clustered systems that rely on the Fuse Management Console, built on Zookeeper. While it will not be used in this tutorial, most of the required infrastructure is included in these scripts.
/etc/sysconfig/camq
JBOSS_AMQ_HOME=/opt/jboss-a-mq
ACTIVEMQ_HOME=/opt/apache-activemq
FABRIC_SCRIPTS_HOME=/root/src/external-mq-fabric-client/scripts
CLUSTER_DATA_DIR=/srv/fuse
CONTAINER_USERNAME=admin
CONTAINER_PASSWORD=admin
CONTAINER_SSH_HOST=host117.phx.salab.redhat.com
CONTAINER_SSH_PORT=8101
ZOOKEEPER_PASSWORD=admin
ZOOKEEPER_URL=host117.phx.salab.redhat.com:2181
/etc/init.d/camq
#!/bin/bash
#
# camq This starts and stops rngd
#
# chkconfig: - 99 01
# description: starts clustered amq server
#
# processname: /sbin/rngd
# config: /etc/sysconfig/camq
# pidfile: /var/run/camq.pid
#
# Return values according to LSB for all commands but status:
# 0 - success
# 1 - generic or unspecified error
# 2 - invalid or excess argument(s)
# 3 - unimplemented feature (e.g. "reload")
# 4 - insufficient privilege
# 5 - program is not installed
# 6 - program is not configured
# 7 - program is not running
#
# Source function library.
. /etc/init.d/functions
# Check config
test -f /etc/sysconfig/camq || exit 6
source /etc/sysconfig/camq
KARAF_CLIENT=$JBOSS_AMQ_HOME/bin/client
AMQ=$JBOSS_AMQ_HOME/bin/amq
test -x $AMQ || exit 5
test -x $KARAF_CLIENT || exit 5
RETVAL=0
# Logic to handle naming and case problems
if [ “$2” == “east” ]
then
profile=”east”
cap_profile=”East”
elif [ “$2” == “west” ]
then
profile=”west”
cap_profile=”West”
fi
pidfile=”/var/run/camq.pid”
prog=”/usr/lib/jvm/java/bin/java”
#OPTIONS=”-server -Xms128M -Xmx512M -XX:+UnlockDiagnosticVMOptions -XX:+UnsyncloadClass -XX:PermSize=16M -XX:MaxPermSize=128M -Dcom.sun.management.jmxremote -Djava.endorsed.dirs=/usr/lib/jvm/java/jre/lib/endorsed:/usr/lib/jvm/java/lib/endorsed:JBOSS_AMQ_HOME/lib/endorsed -Djava.ext.dirs=/usr/lib/jvm/java/jre/lib/ext:/usr/lib/jvm/java/lib/ext:JBOSS_AMQ_HOME/lib/ext -Dkaraf.name=A-MQ-${cap_profile} -Dorg.fusesource.mq.fabric.server-default.cfg:config=JBOSS_AMQ_HOME/etc/activemq-${profile}.xml -Dkaraf.instances=JBOSS_AMQ_HOME/instances -Dkaraf.home=JBOSS_AMQ_HOME -Dkaraf.base=JBOSS_AMQ_HOME -Dkaraf.data=JBOSS_AMQ_HOME/data -Djava.io.tmpdir=JBOSS_AMQ_HOME/data/tmp -Djava.util.logging.config.file=JBOSS_AMQ_HOME/etc/java.util.logging.properties -Dkaraf.startLocalConsole=false -Dkaraf.startRemoteShell=true -classpath JBOSS_AMQ_HOME/lib/karaf-jaas-boot.jar:JBOSS_AMQ_HOME/lib/karaf.jar org.apache.karaf.main.Main”
OPTIONS=”-Xms1G -Xmx1G -Djava.util.logging.config.file=logging.properties -Dcom.sun.management.jmxremote -Djava.io.tmpdir=/tmp -Dactivemq.classpath=$ACTIVEMQ_HOME/conf -Dactivemq.home=$ACTIVEMQ_HOME -Dactivemq.base=$ACTIVEMQ_HOME -Dactivemq.conf=$ACTIVEMQ_HOME/conf/ -Dactivemq.data=$CLUSTER_DATA_DIR -jar $ACTIVEMQ_HOME/bin/activemq.jar start xbean:file:$ACTIVEMQ_HOME/conf/activemq-$profile.xml”
status(){
echo “bean org.apache.activemq:brokerName=amq,service=Health,type=Broker
get CurrentStatus” | java -jar /root/jmxterm.jar -l service:jmx:rmi://$HOSTNAME:44444/jndi/rmi://$HOSTNAME:1099/karaf-A-MQ-${cap_profile} -u admin -p admin -n| grep Good
true
RETVAL=$?
exit $RETVAL
}
start(){
echo -n $”Starting AMQ server”
nohup $prog $OPTIONS &>/dev/null &
echo $! > ${pidfile}-$profile
RETVAL=$?
if test $RETVAL = 0 ; then
touch /var/lock/subsys/camq-$profile
fi
return $RETVAL
}
stop(){
echo -n $”Stopping AMQ server”
killproc -p $pidfile-$profile -d2
RETVAL=$?
echo
rm -f /var/lock/subsys/camq-$profile
return $RETVAL
}
restart(){
stop
start
}
usage(){
echo “Usage: $0 {status PROFILE|start PROFILE|stop PROFILE|restart PROFILE}”
exit 3
}
test $2 || usage
# See how we were called.
case “$1” in
status)
status
;;
start)
start
;;
stop)
stop
;;
restart)
restart
;;
*)
usage
esac
exit $RETVAL
/etc/init.d/camq-east
#!/bin/bash
/etc/init.d/camq $1 `basename $0| cut -f2 -d'-'`
/etc/init.d/camq-west
#!/bin/bash
/etc/init.d/camq $1 `basename $0| cut -f2 -d'-'`
Cluster Configuration File
This configuration file was generated by Luci for a three node cluster built in the Solutions Architect’s Lab at Red Hat (not the Crunchtools Lab). It is provided for guidance and may require additional tuning for your environment.
/etc/cluster/cluster.conf
Read it. Thanks!