---
# Core Builds in the Age of Service
**URL:** https://crunchtools.com/core-builds-service/
Date: 2014-12-03
Author: fatherlinux
Post Type: post
Summary: Background As legacy applications are redesigned for the cloud, they are converted to run in a stateless manner. In newly designed applications, data flows between application code, messaging infrastructure, caches and databases seamlessly even during individual node failures of any one subsystem. When an active node fails, a new one is instantiated and placed backContinue Reading "Core Builds in the Age of Service" →
Categories: Articles
Tags: Container Engines, Kubernetes, OpenShift, OpenStack, RHEL, Systems Administration
Featured Image: https://crunchtools.com/wp-content/uploads/2014/11/infrastructure.jpg
---
# Background
As legacy applications are redesigned for the cloud, they are converted to run in a stateless manner. In newly designed applications, data flows between application code, messaging infrastructure, caches and databases seamlessly even during individual node failures of any one subsystem. When an active node fails, a new one is instantiated and placed back into the pool, but what happens when the infrastructure required to build a replacement node fails?
As infrastructure architects and support teams begin to engage in the process of providing a store front of core builds and services for their internal customers, service contracts will become increasingly important. This article will outline some practical procedures for building, testing, and maintaining images, while at the same time facilitating a culture of learning within infrastructure teams guided by DevOps.
## Industrial Service Contracts
Since, managing computer infrastructure is often compared to manufacturing and process engineering, it is logical to discuss industrial service contracts. Often, manufacturers will pay another company to maintain and repair the infrastructure used to support a given industrial process.
For example, there is a company in North East Ohio that makes fiberglass pick-up truck bed liners. Bed liners must be molded, then they must be painted. Not all of the paint sticks to the bed liner, some of it bounces off and dries in the air. This is called over-spray, and if untreated, contributes to atmospheric pollution. The Environmental Protection Agency (EPA) regulates how much excess paint spray can be released into the atmosphere. For this manufacturer, it is advantageous to outsource the maintenance of this air treatment equipment.
Other companies specialize in these industrial process. [Durr AQ](http://www.durr-cleantechnology.com/) offers a program to maintain all of the infrastructure necessary to treat the exhaust air for a painting process. Durr, will maintain the entire air treatment system, including variable drives, electric motors, fans, and exhaust tubing for 5, 10, or even 15 years. Sometimes the contracts are renewed for another 5-10 years for a combined lifecycle of 10-30 years.
Now, imagine that five years into the agreement, one of the large electric motors, called variable drives fails. Durr, is required to replace it with a comparable part that meets the horsepower requirements and can interface with the control system. Imagine if Durr disregarded this information, and instead replaced it with a more powerful/efficient engine that actually pulled too much air and caused problems with the paint surface on the bed liners?
During the length of the contract, Durr must meet the paint process specifications. Re-engineering the air treatment process is just too expensive. That doesn't mean that parts can't be upgraded, but in our example, air flow would have to remain at the same rate to meet the requirements of the painting process. Core builds and network services are no different. They are a sub-component of the application and must meet the service contract. If the service contract changes, engineering must make costly modifications to the application to adapt to the new core build. Treating air pollution is a different core competency than painting truck beds. The same applies to writing Java applications versus supplying core builds.
## Industry Trends
Essentially, Amazon Web Services, Red Hat, and Google *supply* services to developers and operations staff. These suppliers engineer, install, configure and maintain their products to be consumed over a certain lifecycle. As corporate IT moves to this model, they will in turn, become service providers to their internal customers. Core builds will become internal products and roles will change. Systems administrators and project managers will become engineers and product managers respectively. Internal IT will build and maintain products which meet a process specification during the length of the service contract.
These new core builds will have release notes, technical notes, bug trackers, service contracts, and life cycles documented. They will be treated as software in the supply chain instead of a piece of infrastructure which changes as rarely as possible. They will become full fledged products which can be relied upon by the development teams because of service contracts.
## Deployment Phases
For the purpose of this article, we will divide deployment into two main phases. Typically, there is a [build and a run phase](http://www.forbes.com/sites/ciocentral/2012/05/14/brokerintegrateorchestrate-the-new-it-operating-model/), and that is reflected in the teams responsible for each. This article is specifically targeted at the build phase. Common automation strategies in the build phase include Kickstart, Dockerfile, and Vagrantfile. Common automation technologies in the run phase include Puppet, Chef, CFEngine, and Ansible.
[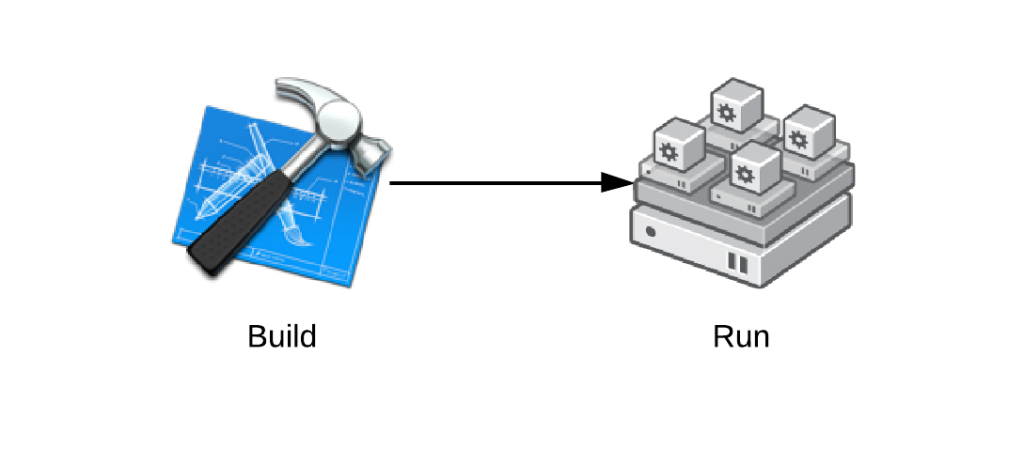](http://crunchtools.com/wp-content/uploads/2014/05/Core-Builds-Build-Run.png)
Many deployment architectures blur the lines between these two phases, especially when build and run are controlled by the same team,. This can including use of tools like puppet in the build phase. The divide is more clear, when one deploys at Amazon or Rackspace. The run team often uses an image built by the provider without thinking about how it get's built, where it comes from, or how long it will be support for. The provider should give clear guidance on what the service contract for this image is, but this is lacking in the current supply chain.
## Rolling Releases & Versions
Before we continue, I want to address one final thing; the concept of a rolling release. Many *consumer* Software as a Service providers have the concept of a rolling release. For example, GMail, Yahoo Mail, do not provide version numbers. One day, a user logs in and the interface looks completely different. A user is essentially left to figure out where to click and how to get their mail. This works with consumers.
With business software, service contracts are much more important. Salesforce.com does have versions. This is because many users build applications against the APIs, etc. Operating systems incorporated in core builds fall into this category of software. This version number essentially governs the service contract. The service contract may have a mechanism by which features can be added in a rolling mechanism, but backwards compatibility is always a concern.
Operating systems are typically released in this mechanism of versions. These versions are an opportunity to redefine the service contract. This is critical in an open source supply chain where things can change quite quickly in the upstream projects
# Core Builds & Products
In this article, I will treat any baseline operating system as a core build. There are two core mechanisms for providing a baseline operating system; image and blueprint. Provisioning from an image has the advantage of being able to include large amounts of software, while a blueprint has the advantage of being easily understood, reproduce-able and automated. These mechanisms are not mutually exclusive. For example, [Docker](http://crunchtools.com/a-practical-introduction-to-docker-containers/) and [Project Atomic](http://www.projectatomic.io/) are providing more granularity to [the software supply chain](http://crunchtools.com/open-source-supply-chain/).
As virtualization became the standard, deploying from images gained popularity. With the advent of OpenStack and AWS, using an image based deployment is really the only mechanism in common use.
While image deployment is becoming the standard, the methodology for building the images is still very much up for debate. In this article, I will explore several architectures for deployment in the context of the over all [software supply chain](http://crunchtools.com/open-source-supply-chain/).
## Architectures
- **Runbook**: Documents human processes, like how to modify and commit the automation code and architectural decisions. The runbook should also contain background information and philosophy on the architecture of the system. This provides guidance and justification for architectural decisions to future team member who interact with the system. This is a key component in curbing the temptation to rebuild things from scratch. Often misunderstandings or lack of information on background lowers productivity and increases the likelihood of scrapping the current solution.
- **Automation**: Contains blueprint of how a the operating system should be installed in the image. This could be a Kickstart, Vagrantfile, Dockerfile, or custom automation to build AMIs or Glance images.
- **Image**: Contains binary data for deployment of operating system. This could be an AMI in Amazon, a Glance image in OpenStack, a Template in VMWare or a Docker repository in a private registry.
- **Deployment**: Operating instance used for development, test, and production instances of application, middleware or other infrastructure.
### Kickstart Architecture
Historically, [Kickstart](http://fedoraproject.org/wiki/Anaconda/Kickstart) has been the preferred method for deploying Red Hat Enterprise Linux and derivatives. This had the advantage of blueprinting what went into the operating system when it was first deployed. The downside was that, every time a system was deployed a new set of transactions had to be enacted. Also, the kickstart infrastructure had to be working flawlessly or deployments couldn't happen.
[](http://crunchtools.com/wp-content/uploads/2014/05/Core-Builds-Kickstart.png)
### Image Architecture
As virtualization became more common, deploying from images gained in popularity. This was especially popular with Windows administrators because that operating system grew from the desktop and so many tasks were originally done by hand. This was and still is a popular method of deployment for very handcrafted images for [systems of record](http://www.forbes.com/sites/joshbersin/2012/08/16/the-move-from-systems-of-record-to-systems-of-engagement/).
[](http://crunchtools.com/wp-content/uploads/2014/05/Core-Builds-Image.png)
### Kickstart and Image Architecture
The following is a basic architecture incorporating both Kickstart and images in one unified architecture. The end systems are provisioned from an image, but the images themselves are built with some form of automation. This is a very popular architecture with Red Hat Enterprise Linux deployments because it confers advantages of both legacy architectures.
[](http://crunchtools.com/wp-content/uploads/2014/05/Core-Builds-Kickstart-Image.png)
### Dockerfile and Image Architecture
The following is a basic architecture incorporating both Dockerfile and images in one unified architecture. The end systems are provisioned from an image on a registry server, but the images themselves are built with Dockerfiles. This is a very popular architecture with many distributions of Linux using containers.
[](http://crunchtools.com/wp-content/uploads/2014/12/Core-Builds-Dockerfile-Image.png)
# Provenance & The Software Supply Chain
The operating system has always been part of the [software supply chain](http://crunchtools.com/open-source-supply-chain/), but with highly automated build processes, testing and certification of service contracts becomes a reality. Product teams can now rely on the upstream supply chain to [guarantee interface consistency](http://crunchtools.com/deep-dive-rebase-vs-backport/) during the lifetime of their product. Furthermore, this interface consistency can be tested and verified after building new versions, but before being released into the service catalog.
## Service Catalogs
The word service catalog is used to describe business solutions such as a ticket system, as well as, technical solutions such as a [Docker Registry](http://crunchtools.com/practical-docker-registry/) server. For the point of this article, I will be using the technical definition. For Docker, the most common distribution method would be through a Registry server. With OpenStack, the most common distribution mechanism would be Glance.
## Red Hat Enterprise Linux & Docker Images
In the following example, Red Hat provides a standard Red Hat Enterprise Linux (RHEL) Docker build which is ran through a strict engineering process. The RHEL build has strict [API/ABI guidelines](http://crunchtools.com/deep-dive-rebase-vs-backport/) and specific dates through which this service contract is good. Consumers of this software supply chain can then use a Dockerfile as a blueprint to systematically change the image. Modifying an image which comes from a known good starting point with a strong service contract gives the resulting image provenance. The customized image may then undergo a set of automated tests to verify service contracts.
These images would then be distributed through a [private Docker Registry Server](http://crunchtools.com/practical-docker-registry/)
[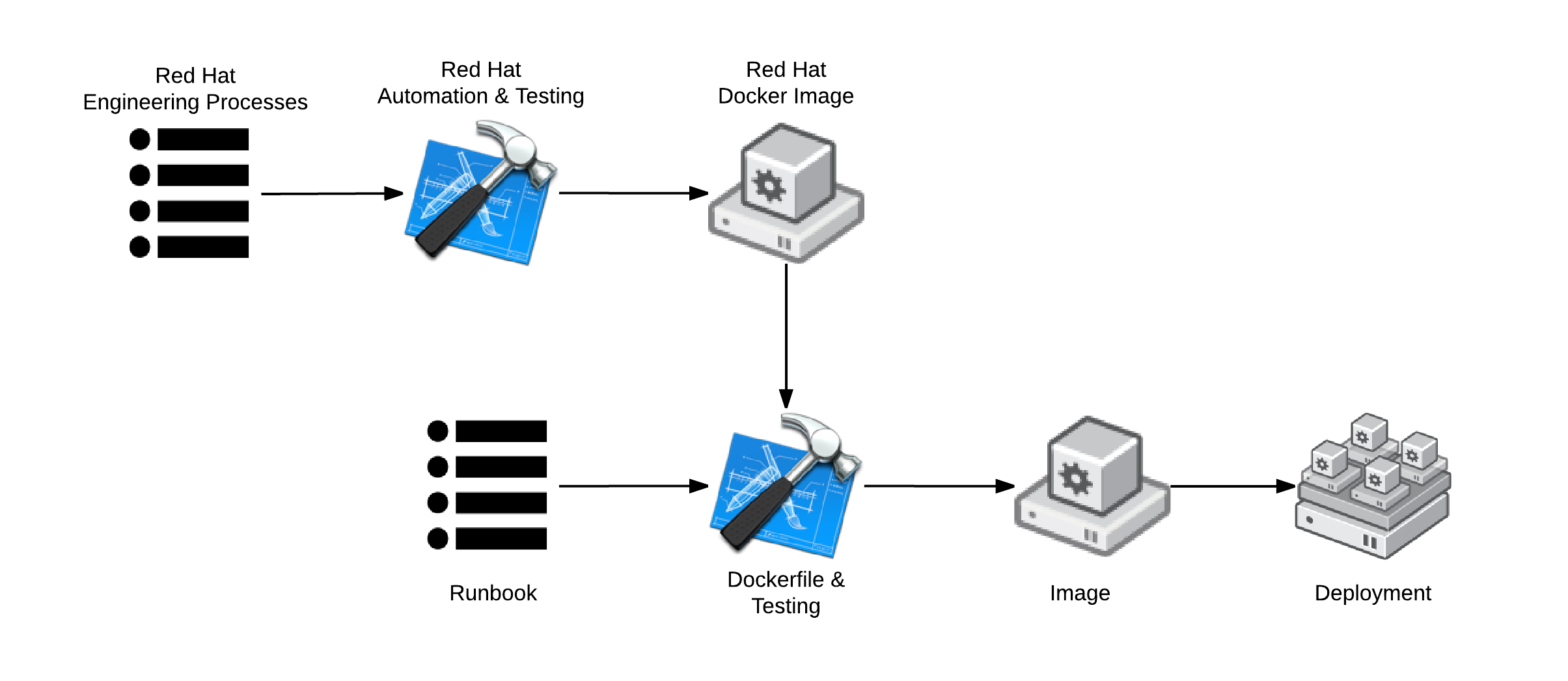](http://crunchtools.com/wp-content/uploads/2014/12/Core-Builds-Provenance-The-Software-Supply-Chain.png)
## Red Hat Enterprise Linux & OpenStack Images
As another example, Red Hat provides a standard RHEL Glance image which is ran through a similar engineering processes as the Docker image and ISO files. These Glance images can be taken and modified in a systematic way with [Diskimage-Builder](https://github.com/openstack/diskimage-builder). Again, this provides the resultant images with provenance and a strong service contract.
Furthermore, as part of the deployment, the final image can be modified with [Heat](https://github.com/openstack/heat-templates) to create customizations for specific workloads such as [OpenShift](https://github.com/openstack/heat-templates/tree/master/openshift-origin). Heat template coding can be simplified by relying on guaranteed customizations (service contracts) within the final image provided in Glance.
[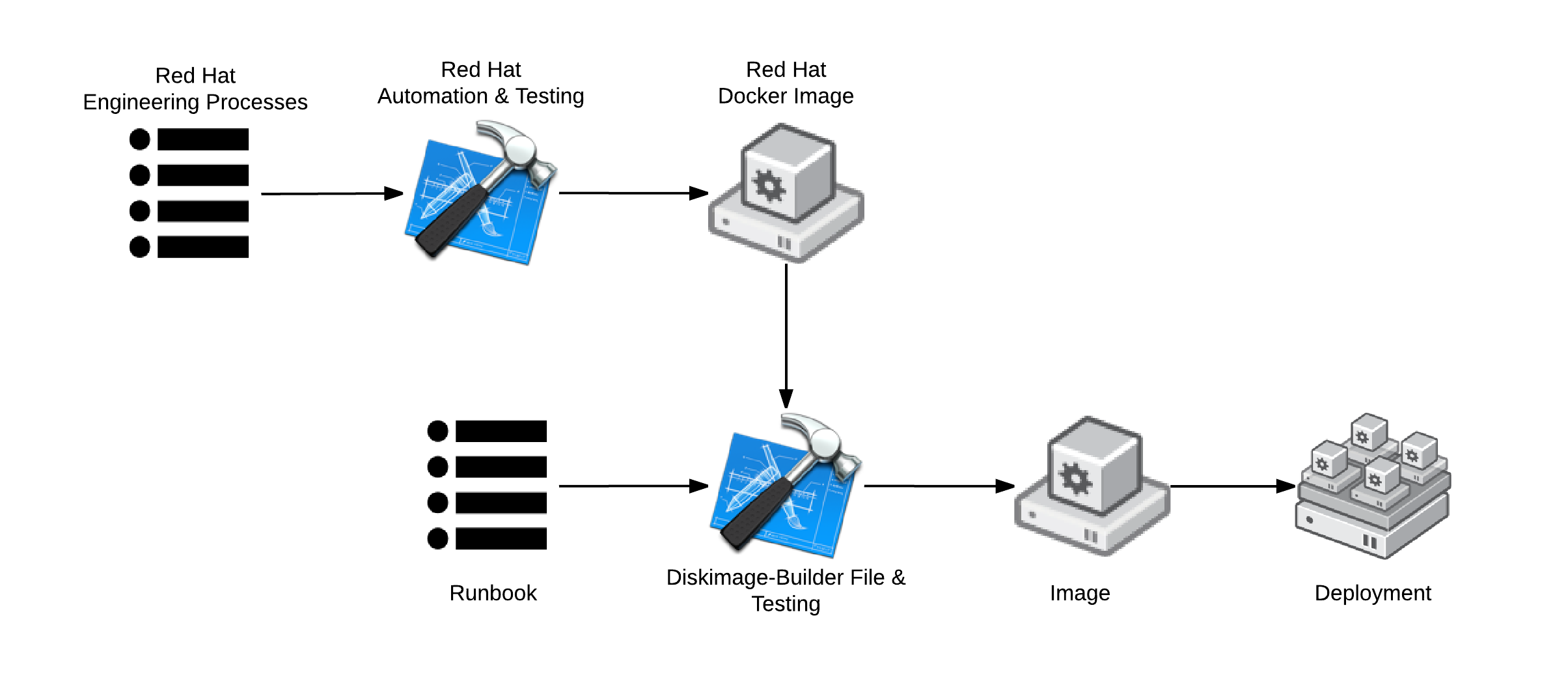](http://crunchtools.com/wp-content/uploads/2014/12/Core-Builds-Provenance-The-Software-Supply-Chain-OpenStack-Copy.png)
# Image Maintenance & Processes
Image maintenance is very different than traditional core build maintenance. The concept of being a component in the supply chain is much stronger, and therefore must be treated differently.
Historically, when a core build was modified, the systems administrator would be careful not to change something that would break things. If the systems administrator did break something, they would go back and quickly fix it.
In the modern service model, the engineers that produce the image may not be the same technical users that consume the image. This separation of roles, means that consumers may rely on features of the core build that the producing engineer may not be familiar with. Consumers of the core builds or images may have extremely sophisticated requirements. Gathering, and maintaining these requirements will result in extra tooling and testing.
## Best Practices
The following is a list of tools and processes that should be considered when moving to a service model
- **Bug Tracker**: Consumers need to have a mechanism to report bugs in the the core build/image.
- **Runbook**: This is a place where engineers will track architectural decisions about the core build. They will also record how to make commits to the core build
- **Revision Control System**: Since core builds will be built automatically with a Dockerfile or Diskimage-Builder elements file, they should be change controlled with some thing like Git. This allows engineers to track and record metadata about each commit.
- **Public Documentation**: Supported architecture and patterns of consumption should be documented here, as well as links to upstream documentation. For example, if the image is built off of RHEL 6.5, the RHEL Administration Guide, RHEL Deployment Guide, etc should be linked here to help end users understand what version of the upstream OS this core build is built from.
- **Release Notes**: Features of the core build should be documented here for public consumption. Links to upstream release notes should be provided here.
- **Technical Notes**: Service contract and life cycle information should be recorded here so that this information is public. Links to upstream technical notes should be provided here.
## Handling Upgrades
In the service model, core build upgrades become an engineering task. They require diligence and tracking of features. This will require a planning phase, a build phase, and a lifecycle. Each of these will be influenced by the upstream products involved.
Today, many customers do not update their core build with every [dot release of RHEL](http://crunchtools.com/deep-dive-rebase-vs-backport/). There are several reasons why customers do not upgrade with every version. Workload type, uptime, risk, level of effort, and commercial software vendors are common reasons.
In the age of service, many of the applications will be [Systems of Innovation](http://www.gartner.com/newsroom/id/1923014), or [Systems of Differentiation](http://www.gartner.com/newsroom/id/1923014) which by their nature, require a faster pace of change. Furthermore, many of these applications will be developed in house. This will require image builders to be very product focused with all of the associated expectations including tested service contracts, release notes, lifecycles, etc.
### Features, Bug Fixes & Resolutions
During the lifecycle of the core build, problems will be identified and tracked. The core builds will incorporate bug fixes, features, and security patches from the upstream distribution. Downstream will be customized for different workloads within the customer's environment. This means, that core builds may also include work arounds.
In a Red Hat environment, the following types of changes may be incorporated in the core build. During the lifecycle of the core build, it will be important to track these changes and capture any problems which result from the changes.
- **Red Hat Security Advisories (RHSA)**: Security fixes are released during dot upgrades (Ex. RHEL 6.5 -> 6.6) or asyncronously (Ex. during the lifecycle of RHEL 6.5)
- <**Red Hat Bug Advisory (RHBA)**: Bug fixes are typically released during a dot upgrade or major upgrade. /li>
- **Red Hat Enhancement Advisory (RHEA)**: Enhancements are typically released during a dot upgrade or major upgrade
- **Red Hat Work Arounds**: These can be provided by a [Red Hat Knowledge Base Article](https://access.redhat.com/solutions/267383), or from [Red Hat Global Support Services](https://access.redhat.com/support/offerings/production/)
- **Custom Work Arounds**: These can be developed in house, or developed through the community. This is an [example at StackExchange](http://stackoverflow.com/questions/26539386/ssh-issue-of-docker-in-redhat-6-5). Changes developed in the community should follow a process similar to a code review and could even be [reviewed by Red Hat Support](https://access.redhat.com/support/offerings/production/soc)
## Testing
To guarantee service contracts over the life cycle of a core build, engineers will need to develop testing suites which capture lessons learned and key features in the infrastructure. As bugs are nailed, tests will need to be put into the test suite to prevent future regressions.
The following drawing outlines an architecture to capture bugs, feature requests, security problems, architectural problems and their associated resolutions. As these resolutions are implemented, meta data should be captured and placed in the runbook. This run book will serve as engineering guidelines for future commits to the core build. It will also start to serve as guiding philosophy for how things should be automated. Finally, the runbook will capture architecture. Something as simple as a wiki can serve as the runbook as long as templates are developed for consistent documentation.
The runbook should give background to future engineers on why and how tests were developed. It should also describe the architecture and thought processes behind test development. Under optimal conditions, a resolution should not be considered complete until a test is developed, and documented.
Testing should be automated similar to a continuous integration environment with Jenkins. Every time a new Glance image or Docker Registry image is pushed to a test server, it should be run and tested before being moved to production.
[](http://crunchtools.com/wp-content/uploads/2014/12/Core-Builds-Testing.png)
# Summary
In the age of service, core builds become a product in the supply chain of software relied upon by applications. This will require the development of sophisticated engineering practices. Many cloud providers, such as Google and Amazon, have already moved to this model. Systems Administration is broken into different roles, some become Site Recovery Engineers, while others become build engineers. While some people remain Project Managers, many become Technical Program Manager or Product Managers.
Core builds become certified images with documentation, release notes, known bugs, and engineering schedules. All of this will provide more reliability and better trust between the operations and development community.
---
## Categories
- Articles
---
## Navigation
- [Home](https://crunchtools.com/)
- [Articles](https://crunchtools.com/category/articles/)
- [Events](https://crunchtools.com/category/events/)
- [News](https://crunchtools.com/category/news/)
- [Presentations](https://crunchtools.com/category/presentations/)
- [Software](https://crunchtools.com/software/)
- [Beaver Backup](https://crunchtools.com/software/beaver-backup/)
- [Check BGP Neighbors](https://crunchtools.com/software/check-bgp-neighbors-nagios/)
- [Chev](https://crunchtools.com/software/chev-check-vulnerabilities-script/)
- [Graph BGP Neighbors](https://crunchtools.com/software/grpah-bgp-neighbors/)
- [Graph MySQL Stats](https://crunchtools.com/software/graph-mysql-stats/)
- [Graph Sockets Pipes Files](https://crunchtools.com/software/graph-sockets-pipes-files/)
- [MCP Servers](https://crunchtools.com/software/mcp-servers/)
- [Petit](https://crunchtools.com/software/petit/)
- [Racecar](https://crunchtools.com/software/racecar/)
- [Shiva](https://crunchtools.com/software/shiva/)
- [About](https://crunchtools.com/about/)
- [Home](https://crunchtools.com)
## Tags
- Container Engines
- Kubernetes
- OpenShift
- OpenStack
- RHEL
- Systems Administration