---
# Part II: Why Is There No Docker in OpenShift 4 and RHEL 8?
**URL:** https://crunchtools.com/why-no-docker/
Date: 2019-05-17
Author: fatherlinux
Post Type: post
Summary: In Part I: Is Docker Supported in OpenShift 4 and RHEL 8? I explained that the the Docker daemon will not be supported in new Red Hat products, but that Docker images will be. The next question people always ask me is, “Why? I thought you guys love Docker? I’m confused.” There are many reasonsContinue Reading "Part II: Why Is There No Docker in OpenShift 4 and RHEL 8?" →
Categories: Articles
Tags: Community, Container Engines, Container Tools
Featured Image: https://crunchtools.com/wp-content/uploads/2018/03/About.png
---
In [Part I: Is Docker Supported in OpenShift 4 and RHEL 8?](http://crunchtools.com/docker-support/) I explained that the the Docker daemon will not be supported in new Red Hat products, but that Docker images will be. The next question people always ask me is, "Why? I thought you guys love Docker? I'm confused." There are many reasons why Red Hat products are moving away from Docker as the container engine, some are **technical**, some are **community** based, and some are **business** based. Let's break it down.
## Technical
**First**, the Docker engine is a lot of things to a lot of people and it's one big daemon ([#nobigfatdaemons](https://twitter.com/hashtag/nobigfatdaemons?lang=en)). Some people build with it, others use it for Kubernetes, some build home grown orchestration platforms. The Docker engine was designed, built, and released as one, big daemon. This made it easy to download, install and play with. This likely had a positive effect on people's ability to understand what it did, how to use it, and thereby sped up adoption. But, five years later, this early design decision is holding features back.
The Docker engine is tied to the daemon model, making it difficult to change its architecture for different use cases. As an example, who wants to [run a whole daemon in their home directory](https://medium.com/@tonistiigi/experimenting-with-rootless-docker-416c9ad8c0d6) to run rootless containers? Short answer, nobody, that's crazy. Podman shines here. How about remotely inspecting an image? That would require using a client (docker) to talk to a daemon (dockerd), to talk to another daemon (containerd) to talk to another daemon (registry server). With Skopeo, you just run the command and it talks directly to the registry server to remotely inspect container images. The same is true with building images. Why run a daemon to create tarballs, and json files ([OCI Image Specification](https://www.opencontainers.org/news/2016/04/14/celebrating-the-open-container-initiative-image-specification)), and why should you have to be root? You shouldn't. Breaking container work streams (find, inspect, build, run, etc) up into smaller tools is so much more elegant.
**Second**, the Docker engine doesn't move at the same speed as Kubernetes. It's on a totally different lifecycle (same with containerd). This makes it difficult to add features in the engine to support the Kubelet. Kubernetes might be ready to do something at the higher layers, but have to wait on the engine to have a new release months later. It also makes it difficult to support the Kubelet and the engine over the same number of years so that users get value out of the particular combination (something really valuable for open source products like OpenShift). Ask yourself this simple question. What combinations of Kubernetes are tested and guaranteed to work with what versions of Docker? The answer is, whatever you test together, but that might be different than the combination that everybody else is using. There's no easy way to know, unless you copy what one of the big vendors (Google, Red Hat, Amazon, Microsoft, etc) is doing and essentially hide behind their testing (nothing wrong with that, that's Open Source, but I want more than that).
Now ask yourself that same question with CRI-O? The answer is brain dead simple. CRI-O 1.13 supports Kubernetes 1.13 and only Kubernetes 1.13, not Apache Mesos 1.8.0, not Swarm 1.2.9. No other orchestrator and no other version of Kubernetes is supported by CRI-O 1.13. The same is true with CRI-O 1.14, it only supports Kubernetes 1.14. The same is true with CRI-O/Kube 1.15, 1.16, 1.17 and 2.0, should it ever come :-) When you upgrade Kube, you upgrade CRI-O. Super simple.
**Finally**, the Docker engine is old, and it's adding features slower than ever before. It's one big daemon, which already supports a lot of use cases. The bigger it gets, the harder it is to change the fundamental architecture, making it difficult for the project to experiment with big changes. Because the Docker engine hasn't changed much, people are still building and running containers almost the exact same way as they were 5+ years ago when it was first released. When a piece of software grows in usage as fast as the Docker engine did, it inevitably gets harder and harder to experiment with new features. When users start to trust your software, they come to expect certain behaviors. This is a challenge Red Hat has with RHEL (hence OpenShift). The Docker engine has experienced this problem as well as a slow down in upstream community contributions.
In a world of microservices, it doesn't make sense to run a big monolith anymore (really it never did). Breaking containers up into smaller tools, using the [Unix philosophy](https://en.wikipedia.org/wiki/Unix_philosophy), allows Podman, Buildah, and Skopeo to experiment with new capabilities and iterate much faster than one big daemon which supports Kubernetes, Apache Mesos, and Swarm. Podman, Buildah, and Skopeo share the same image and storage libraries with CRI-O allowing the community to experiment with Podman to test out new things, then move the features into CRI-O as they mature. CRI-O inherits a lot of value from Podman, Buildah, and Skopeo. Podman, Buildah and Skopeo are for humans, and CRI-O is for the Kubelet.
## Community
Any way you measure it, the split of the Docker community project into the Docker CE/EE products, and Moby project led to a huge drop off in upstream contributions. I don't blame Docker Inc. for trying to find a way to monetize their business, it's necessary to keep the community projects flourishing. The Linux Foundation talks about this all the time. Successful businesses lead to more revenue, which leads to healthy investment in community based, open source projects. There is nothing immoral or unethical here. Red Hat does it all the time, and I fully support Docker Inc's right to do this. I just wish they would have done it 2-3 years earlier than they did, when all they had was the Docker daemon and client. It would have been so much simpler, and I think it would have led to a much healthier outcome.
[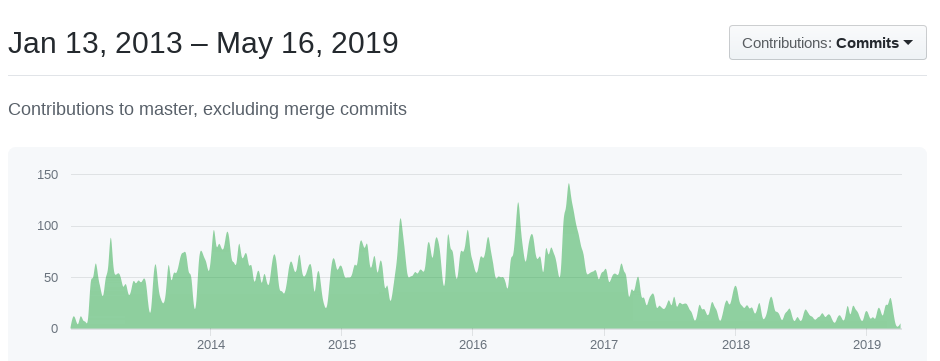](http://crunchtools.com/wp-content/uploads/2019/05/Screenshot-from-2019-05-16-22-15-29.png)
If you search Google for Moby Engine, most of the articles are from 2017 when the split happened. Nobody is excited about the Moby project. There is barely any blog content, nobody seems to be publishing new blogs, and contribution statistics have literally dropped off since the split in 2017.
The split was super confusing for a lot of people who just wanted the Docker engine and the client. When the Moby split happened, the **github.com/docker/docker** repository was moved to **github.com/moby/moby**, which included the Docker daemon, but not the Docker client. A **github.com/moby/cli repository **was never added leaving community members completely confused. The direct conversion of docker/docker to moby/moby helped it retain all of the github stats (forks and stars) of the original project for marketing purposes, but some might call this a bait and switch. In addition to not including the client, many new, confusing projects were added (LinuxKit, BuildKit, etc). All of these new projects were essentially tools to support Docker Inc's products, but never took off in the community. It was the exact opposite of traditional open source, create a community, then a product. When people "open source" existing product code, it rarely works, and when it does, it takes years to grow the community. The vast majority of people just wanted access to the Docker daemon and the Docker client, but with the Moby split in 2017, there was no easy way to just get the daemon and the client from the community.
In fact, there was no easy way to even know what it should be called if you did build it. One might naturally gravitate to calling it the Moby engine and Moby client, but that's not what is built by the Moby github repo, and that's not what the moby/moby repo is even intended to do. Further more, the community never provided guidance for a Moby Engine/Client, nor how to build it. The Fedora community [figured out how to build](https://bugzilla.redhat.com/show_bug.cgi?id=1539161) a moby package, but it still delivers the Docker daemon from the [moby/moby](https://github.com/moby/moby/) github repo, and a client from the [docker/cli](https://github.com/docker/cli) repo. This doesn't make anyone feel warm and fuzzy.
Long story short, the Moby split was a confusing disaster. Even today it's still extremely confusing to anybody wanting just a container engine/client. This clearly led to a drop of in community support. If Docker would have done this split 2-3 years earlier, there would have only ever been a daemon/client, no BuildKit, no LinuxKit, no VPNKit, no other confusing things, just a daemon and client. Then, I think the split could have been done more elegantly and perhaps things would have turned out completely different.
## Business
As stated above, I don't fault a company for needing to make money. A split between a community project, and a pay-for product can be done in a healthy way which benefits the project and allows people to make a living. But, it doesn't appear that this is the case with Docker Inc. They have changed CEOs twice now. The CTO left and many of the founding employees are no longer with Docker Inc. For anybody paying close attention, it doesn't look like Docker Inc. will be around in a year much less 10 years.
Moby has essentially become a single vendor project that's really only fit to support products from Docker Inc. Kubernetes, OpenStack, and the Linux kernel all have healthy contributions from many different vendors. This means that if any one of the vendors goes out of business, or cuts investment, there are others, with successful products to keep contributing to the upstream, community driven projects. This might be OK if Docker Inc. was making loads of money, and increasing their investment in the upstream project, but that just doesn't seem to be the case. in fact, the latest DockerHub hack ([Docker Hub hack exposed data of 190,000 users)](https://www.zdnet.com/article/docker-hub-hack-exposed-data-of-190000-users/), problems with Alpine ([Alpine Linux Docker images ship a root account with no password](https://www.zdnet.com/article/alpine-linux-docker-images-ship-a-root-account-with-no-password/)), and CEOs stepping down ([Steve Singh stepping down as Docker CEO](https://techcrunch.com/2019/05/08/steve-singh-stepping-down-as-docker-ceo/)) all lead one to believe that they are struggling with resources and investment.
In a business environment like this, Red Hat just can't depend on Docker being around to keep contributing to the Docker Engine and Client. It would literally be stupid to base products on a dying community supported by a dying company. Red Hat has to base it's products on thriving communities providing new innovation.
## Conclusions
The Docker Engine changed the world, and to be honest, it hurts a bit to watch it limp along like this. There are a lot of problems with the Docker engine/client. The early design decisions were great for adoption, but have since stunted feature development. The product/project split, really hurt the upstream community contributions, and the main company supporting the community project doesn't appear to be doing well financially. These three sets of factors conspire to create a scenario where it's just untenable to invest in the Moby community and nearly insane to build enterprise products like RHEL 8 and OpenShift 4 on this technology.
The Open Containers Initiative standards allow the upstream, open source, community to move on, to a set of next generation tools, while providing most users a smooth transition from Docker to Podman in Red Hat Enterprise Linux 8, and CRI-O in OpenShift 4.
Follow me on Twitter: [@fatherlinux](https://twitter.com/fatherlinux)
Originally published at: [http://crunchtools.com/why-no-docker/](http://crunchtools.com/why-no-docker/?preview=true&frame-nonce=388d01a716)
---
## Categories
- Articles
---
## Navigation
- [Home](https://crunchtools.com/)
- [Articles](https://crunchtools.com/category/articles/)
- [Events](https://crunchtools.com/category/events/)
- [News](https://crunchtools.com/category/news/)
- [Presentations](https://crunchtools.com/category/presentations/)
- [Software](https://crunchtools.com/software/)
- [Beaver Backup](https://crunchtools.com/software/beaver-backup/)
- [Check BGP Neighbors](https://crunchtools.com/software/check-bgp-neighbors-nagios/)
- [Chev](https://crunchtools.com/software/chev-check-vulnerabilities-script/)
- [Graph BGP Neighbors](https://crunchtools.com/software/grpah-bgp-neighbors/)
- [Graph MySQL Stats](https://crunchtools.com/software/graph-mysql-stats/)
- [Graph Sockets Pipes Files](https://crunchtools.com/software/graph-sockets-pipes-files/)
- [MCP Servers](https://crunchtools.com/software/mcp-servers/)
- [Petit](https://crunchtools.com/software/petit/)
- [Racecar](https://crunchtools.com/software/racecar/)
- [Shiva](https://crunchtools.com/software/shiva/)
- [About](https://crunchtools.com/about/)
- [Home](https://crunchtools.com)
## Tags
- Community
- Container Engines
- Container Tools