
It only takes a couple of quick google searches to realize that people have no idea what a container engine is.
That’s understandable because It was a completely new concept back in 2013. Plenty of good people have tried and failed – see WTF is a Container (not deep enough) or What is Docker and why is it so darn popular? (technical drawing completely wrong). Pfft, look at the Wikipedia Talk page for Docker – people are still confused. As we have more and more people adopting containers, we really need something that explains what a container engine is.
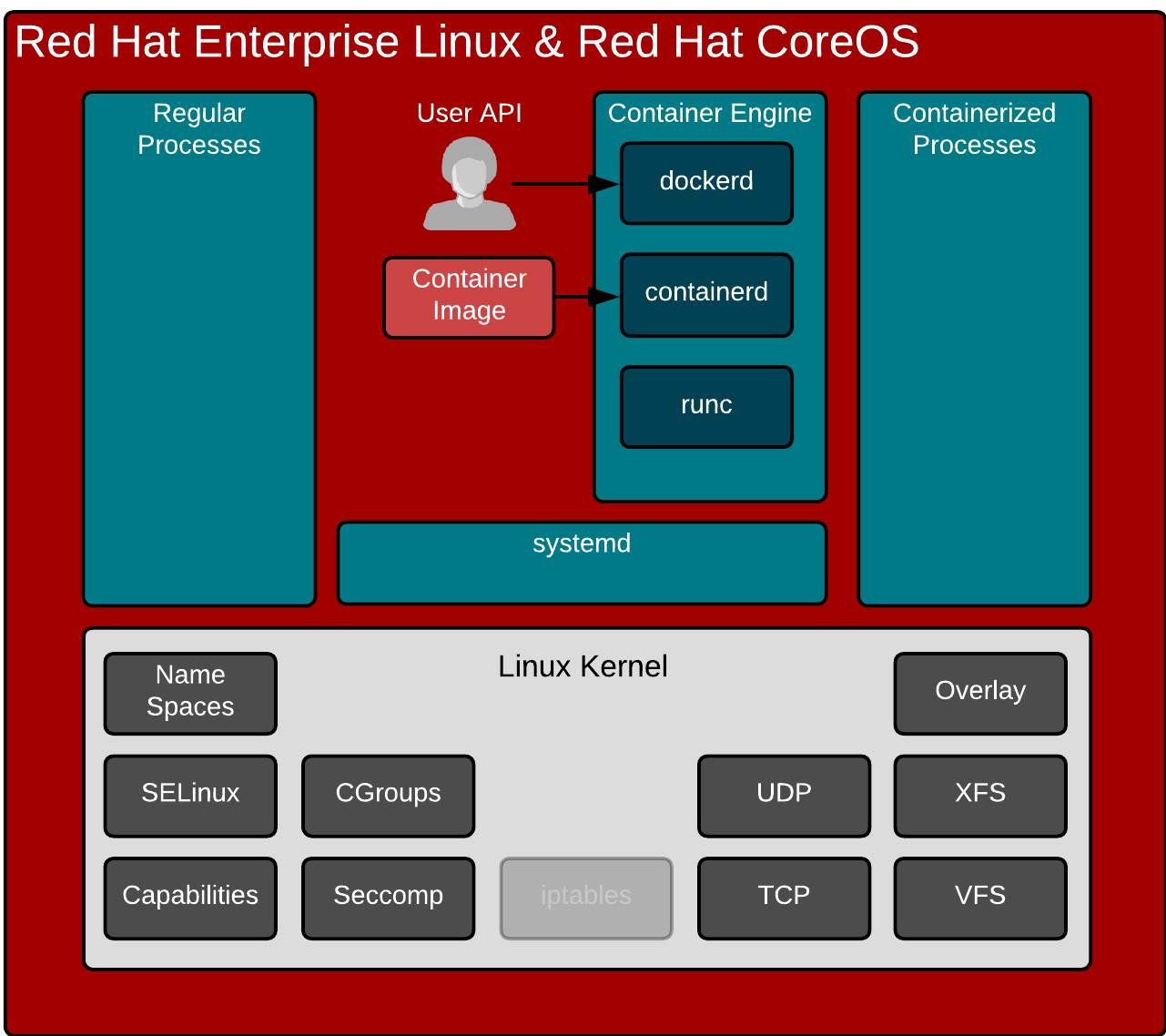
I have pointed out before that Containers Don’t Run on Docker (I got flamed on Reddit), but I have never really explained what a container engine does. I mean, technically. It’s 2018, so let’s do this 🙂
The container engine is primarily responsible for these three main things:
- Provide API/User Interface
- Pulling/Expanding images to disk
- Building a config.json
In all likelihood, many readers won’t fully understand #2, and may not have even heard of #3 – so, I will explain.
Provide API/User Interface
This is actually pretty simple and pretty obvious. When I create containers, I don’t want to compile a C program to use the clone() syscall and setup SELinux rules. I don’t want to code something up to do SECCOMP. I really want to use a simple API and/or command line tool. That’s how the docker command line interface and API were developed.
The question in 2018, what API should we learn and use. Kubernetes is the more important API. But, there are times when you need to get down in the guts of the container engine. For example, when troubleshooting. That’s where Container Runtime Interface (API) and cri-tools come in.
What’s not obvious is the future. Historically, even in Kubernetes clusters, the interface to the container engine has just been the docker command line interface. But, the Kubernetes world has a broader vision of pluggable container engines. The Kubernetes community has developed and implemented the Container Runtime Interface (CRI) as the standard interface for Robots (kubelet) and Humans (crictl) to interact with the container engine. The Kubelet speaks CRI natively to the engine (or a shim like Docker shim), while humans can use the CRICTL tool. If you haven’t heard of CRICTL, check this article.
Pulling/Expanding images to disk
This is a two part process. First, the container engine has to pull the images to a local cache. Then, every time a new container is started, the engine is responsible for mapping it to a copy-on-write instance of the container image. You might also call this a thin snapshot of the container image. Finally, the container engine often adds an extra layer so that data can be written within the container (not that you should really ever do this, but people do). I have grouped these things together because as far a container engine is concerned, they are really only useful together.
The first step is pulling container images – technically this is the set of Image Layers necessary to construct a set of files indicated by a Tag. This is a standardized processes that is governed under the Open Containers Initiative (OCI) Image and Distribution specifications. The image spec defines the content and metadata in the container repository. The distribution spec covers the protocol for pulling the the necessary image layers and metadata from the repository on a Registry Server.
The second step is extracting the image layers to disk when a container is created. This is not governed under any specification, but that’s OK because there are standardized, open source libraries like containers/image and containers/storage. Every time a new container is started, a virtual copy of the set of files constructed from the container image tag is mapped into the container. Many/most people don’t understand that this fundamentally uses operating system technologies like overlayfs or device mapper. Think of this mapping process similar to thin provisioning a VM.
With read-only containers, the step just described is the final step. But, most people don’t run their containers read-only (even though they should). With non-read-only containers, aka writable, the container engine is also responsible for mapping a writable volume over the layers in the container image. Again, this is typically done with overlayfs or devicemapper. This creates a space where data can be written. For example when you exec into a container and echo hello world into a file, it looks and feels like you are writing data into the container. Really, you are just writing data into a copy on write layer.
When you run docker rm, you are really telling the engine to remove this cow layer. When you run docker rmi, you are telling the engine to remove the local image repository (image layers, meta-data and tags) from the cache.
Building a config.json
Finally, the container engine is responsible for creating a config.json and passing it to runc or some other OCI compliant runtime. When the original docker engine was first created, it used LXC to create containers (aka talk to the kernel). Then Docker Inc. wrote an implementation from scratch called libcontainer. Later, Docker contributed that libary to the OCI standards body as a reference implementation called runc. This is a terse, little tool that expects two main command line options:
- A directory which has the expanded contents of one or more container image layers in it
- A file called manifest.json which has a bunch of directives in it
Neither the directory nor the manifest is simple to create by hand. First, let’s explain the directory. When we talk about “pulling an image” technically we aren’t pulling a single container image, we are pulling all the dependent layers from a container repository. To manually get the files you want for a given image tag, you would have to pull and untar all of the dependant layers . The manifest is even more complex because container engines dynamically build them for each container. To build the manifest.json, you would have to determine all of the command line options that you would normally use with the Docker Engine, as well as defaults that are set in the engine, as well as gather some basic data from the container image (such as hardware architecture). Building the directory and manifest is not easy, nor fun – luckily the container engine does all of this madness for us. Thank you CRI-O, containerd, dockerd, and RKT.
Conclusion
Now, after reading this article, you should really know what a container engine does and and have a much better understanding of how a container is created. The next time somebody says the words application virtualization, or container creation, you can really explain how it works.
Finally, it’s often useful to think of containers, and container creation in the larger context of a Container Host. The technologies within a container host, the Kubelet, Container Engine, Container Runtime and operating system kernel all work together to enable containers, especially at cloud scale where containers can come and go by the thousands per second.
As always, leave questions below, or feel free to find me on Twitter: @fatherlinux
Very good explanation. And I agree, most of the people using containers for years have no idea what container really is and what is involved in its inception. Docker made the things simple for everyone obscuring the gorry details from the regular users.